

Contents
Overview
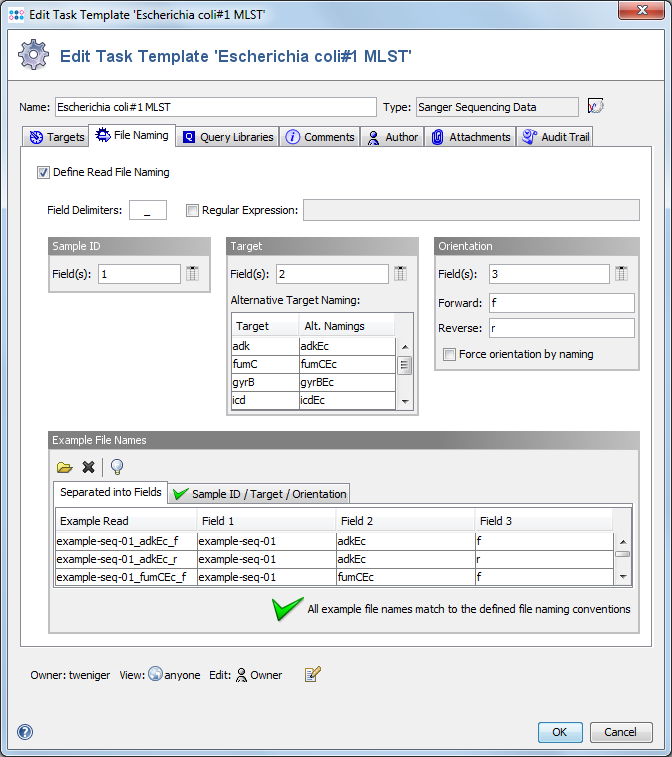
The definition of file naming conventions can be used for batch processing of Sanger sequence files. The name of a read is either the file name or the internal name (e.g., from SCF comments), depending on the settings in the Ridom Typer preferences. The file naming conventions are defined in two steps: first it is defined how the read name should be split into several fields; secondly it is defined how these fields should be used.
Define Field Splitting
Two allow an easy file naming detection, your file names should a delimiting character (like "_") that appears a in all files equally often.
For example the file
- MRSA_056_arcCSa_b.scf
has the delimiter "_" that can be used to split the file name into 4 different fields:
- MRSA
- 056
- arcCSa
- b
It is important that the number of fields is the same in all files (in fact tailing fields that are unimported are not a problem).
For two different file names like
- MRSA_056_arcCSa_b.scf
- MRSA_057_2_arcCSa_b.scf
it is not possible to create a common file naming using the simple delimiter mode.
However, in this case it is possible to use the regular expressions mode. For a detailed description of the usage of regular expression it is referred to Regular Expressions.
Define Field Usage
If the file names are successfully split into different fields, a field or a combination of fields can be assigned to be used as Sample ID, target or orientation.
The fields are referred by their ordinal number (1=first field) combinations are possible with "," (listing) or "-" (range). For the example of above, possible fields and field combinations could be:
1-4 => MRSA_056_arcCSa_b 1,2 => MRSA_056 3 => arcCSa 4 => b
Sample ID
This defines, to which Sample the read should be added, or the ID of the newly created Sample. All reads sharing the same Sample ID name will be added to the same Sample.
Defining the Sample ID is mandatory.
Target
This defines, to which target the read should be added. It must match to a target acronym defined in the Task Template. If the file names are slightly different to acronym defined in the Task Template, alternative target naming can be defined. Several alternative names can be specified, separated by ','.
Defining the target is mandatory.
Orientation
This defines the orientation label of the read. If the found text is equal to the defined forward text, the sequence is treated as forward, or vice versa for reverse. This information is only used to determine the contig orientation, if the signature search and ref.-seq. alignment failed. Activating the Force contig orientation check-box however will override this determination of contig orientation.
Defining the orientation is optional. It is useful if ref.-seq. and signatures can not be defined.
Example File Names
To define and test the file naming conventions, some example files can be loaded and processed into a preview. It is optional to add example files.
If files were added, two different preview tables are shown for them:
- Separated into Fields
- A preview for the fields into which the file names will be split by the given delimiter (or regular expression).
- Sample ID/Target/Orientation
- A preview of the usage of the fields as currently defined. If not all mandatory fields are filled, or if there are inconsistencies, a warning is shown.
FOR RESEARCH USE ONLY. NOT FOR USE IN CLINICAL DIAGNOSTIC PROCEDURES.