
| wiki | search |
Contents |
1 Overview
This tutorial describes how to use the Ridom SeqSphere+ software to analyze Sanger sequence data (e.g., chromatogram files) with Multi Locus Sequence Typing (MLST).
Furthermore, it is explained how to create a Task Template for automated sequence analysis. The MLST scheme for N. meningitidis is used as an example for demonstration purposes. However, by reading this tutorial you should be able to define your own MLST templates for other species.
2 Preliminaries
- Step 1: This tutorial requires a running SeqSphere+ client and server. If not done yet:
- Download and install the SeqSphere+ client and server software on your computer.
- Start the SeqSphere+ server, then start the SeqSphere+ client and initialize the database.
- For evaluation purpose a free evaluation license can be requested.
- Step 2: Download the example data archive SeqSphere_Examples_Sanger_N_meningitidis_MLST.zip for this tutorial, and extract the zip-file on your computer. The example data contains Sanger/CE sequencing data for Neisseria meningitidis MLST of 3 samples of a community outbreak that was published by U. Vogel et al. (J. Clin. Microbiol. 50: 1889, 2012).
3 Defining Project and Task
- Step 1: Create a new Project for use with your sample data with the menu: File | New | Project
- Step 2: Enter a name for your Project (e.g., Neisseria MLST)
- Step 3: Each Project within SeqSphere+ needs to have at least one Task Template associated. Press
 Add Manually in Task Templates section.
Add Manually in Task Templates section.
- Step 4: Press
 Create New
Create New
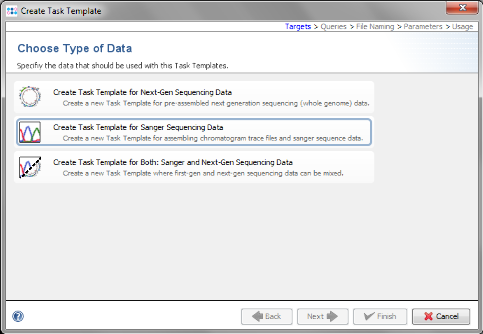
- Step 5: Choose Create Task Template for Sanger Sequencing Data.
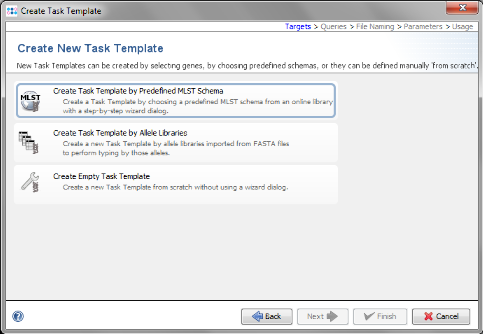
- Step 6: Now choose Create Task Template by Predefined MLST Schema.
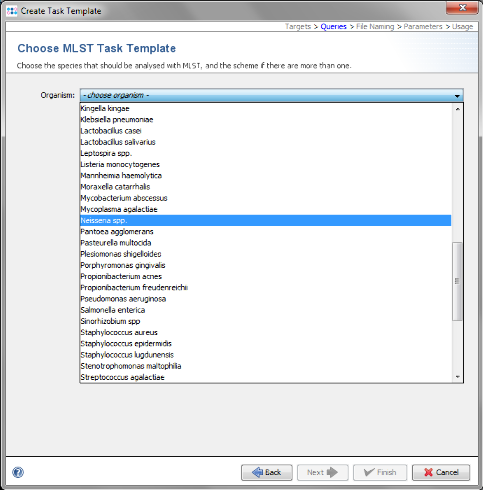
- Step 7: Choose in the organism the entry Neisseria spp. and the data will be downloaded from the public MLST server.
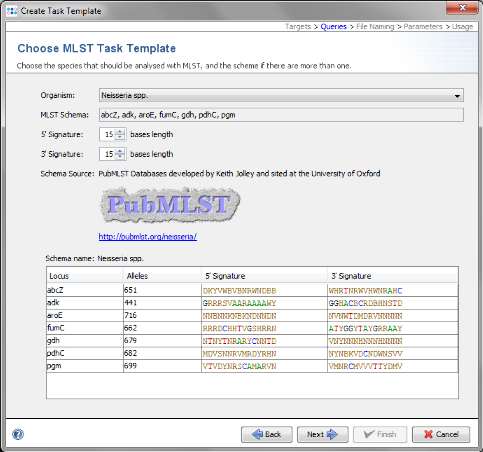
- Step 8: Click Next to continue.
- Step 9: Now choose Define File naming Automatically from Example Files.
- Step 10: The definition of the file naming is important to enable a batch processing of sequence files. Press the
 Add Example Files button, and select all scf-files from the tutorial example data directory and confirm with Open. Then press Next to continue.
Add Example Files button, and select all scf-files from the tutorial example data directory and confirm with Open. Then press Next to continue.
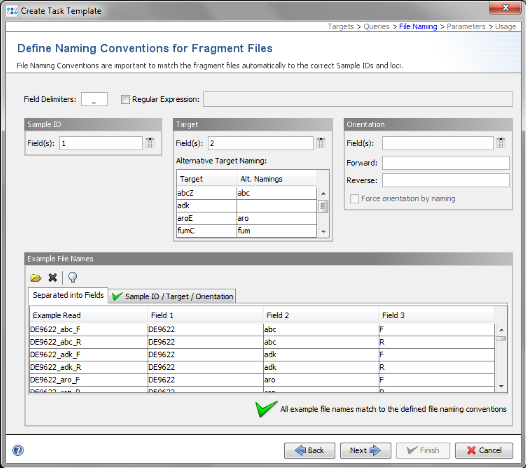
- Step 11: SeqSphere+ tries to guess the file naming from the example files. The green
 on the bottom marks that a file naming was found that matches to all example files. If the file naming is not detected automatically, the Sample ID and target parts of the file name must be configured manually. For the example data it is detected automatically. Click Next to continue.
on the bottom marks that a file naming was found that matches to all example files. If the file naming is not detected automatically, the Sample ID and target parts of the file name must be configured manually. For the example data it is detected automatically. Click Next to continue.
- Step 12: This step shows the Target Parameters for the Task Template (e.g., the quality check parameters). They can be left unchanged. Click Next.
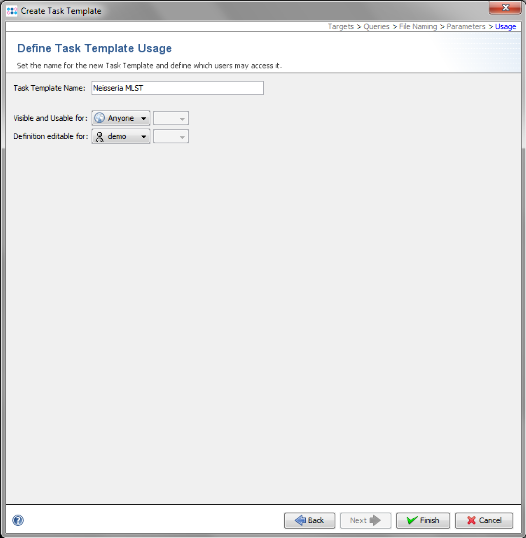
- Step 13: Check the name of your new Task Template, and confirm with Finish. Press OK to save the new Task Template and add it to your Project.
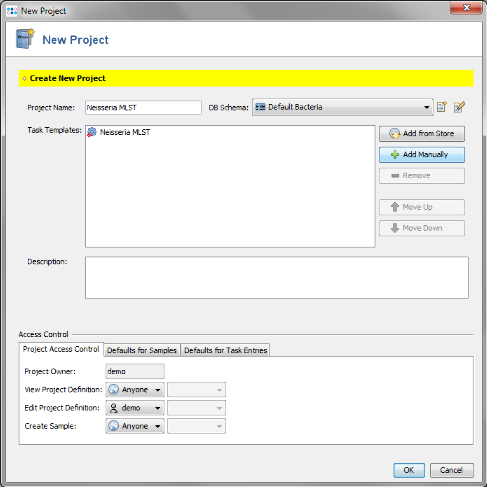
- Step 14: In the top row of the Project window the DB Schema can be selected. This defines the database fields that are available for this Project. For a new Project the DB Schema Default Bacteria is preselected. Press the
 button on the right to see the details.
button on the right to see the details.
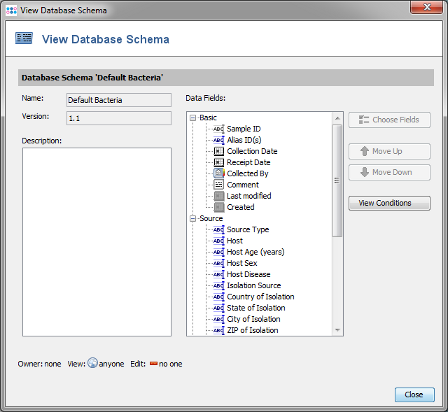
- Step 15: This schema contains already all fields that are normally needed and is compliant with the NCBI BioSample fields. New fields can be added by creating a new Database Schema that extends the default one. For this tutorial the Database Schema is left to default therefore close the window. Then save your Project by confirming with OK.
- Ridom SeqSphere+ is a resequencing software. Once you have setup your project you can literally analyze hundreds/thousands of sequence data automatically.
4 Importing the Sequence Data
- Step 1: Choose from the menu File | Create Samples from Sanger Sequencing Data
- Step 2: Press the
 button above the file browser panel on the left, and choose the directory where you extracted the tutorial example data.
button above the file browser panel on the left, and choose the directory where you extracted the tutorial example data.
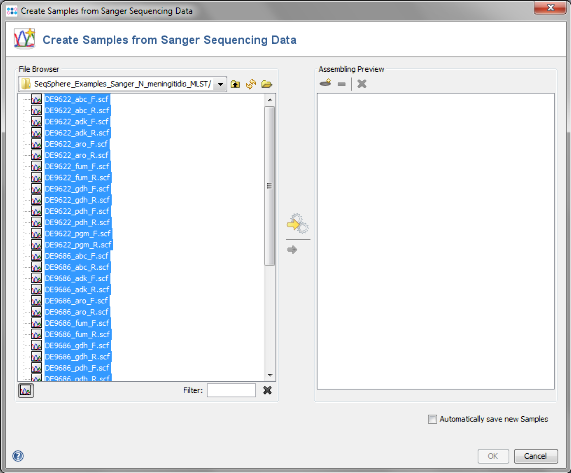
- Step 3: Select the tutorial example data directory or all of the scf-files in it, and press the button
 (Hint: Use CTRL+A to select all files in the directory).
(Hint: Use CTRL+A to select all files in the directory).
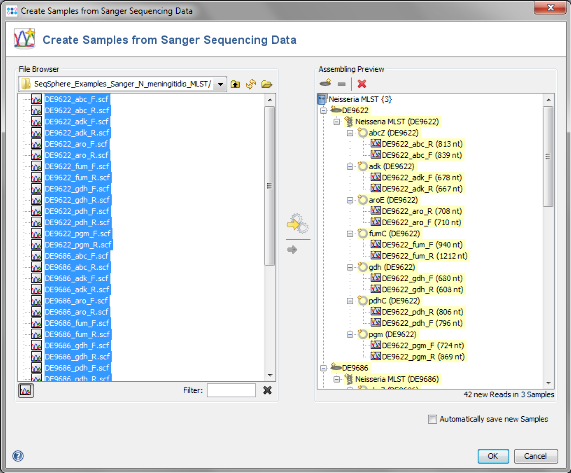
- Step 4: In the upcoming preview dialog select the Project that was just created. The files are now sorted corresponding to the file naming defined above. Each Sample has 7 targets, and each target has 2 chromatograms. Press OK to confirm the preview dialog.
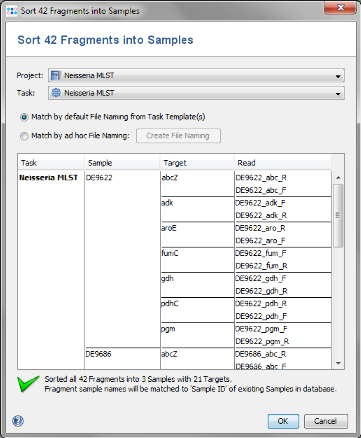
- Step 5: The 42 reads are now sorted into 3 Samples listed in the tree on the right. Each Sample has an MLST Task Entry with 7 targets, one for each locus. Press OK to confirm the dialog and start the assembling.
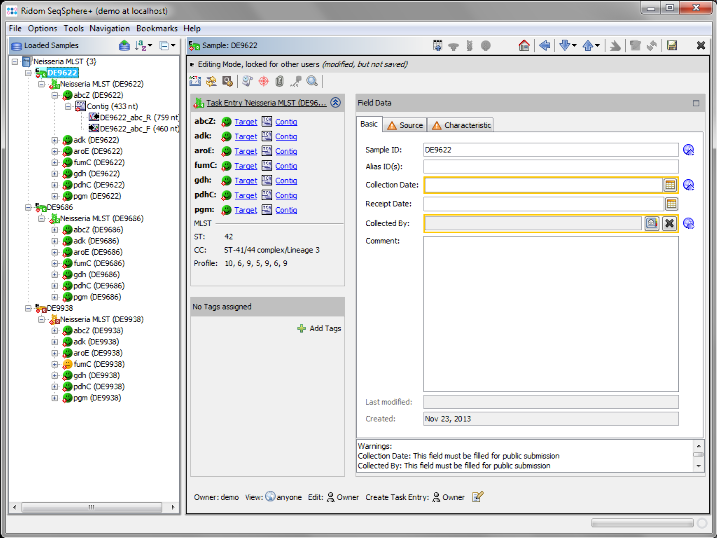
- Step 6: The 3 Samples are now assembled one after the other. They are listed on the navigation tree in the right of the main window. Double-click on the Task Entry item
 Neisseria MLST (DE9622) in the navigation tree of the first Sample DE9622.
Neisseria MLST (DE9622) in the navigation tree of the first Sample DE9622.
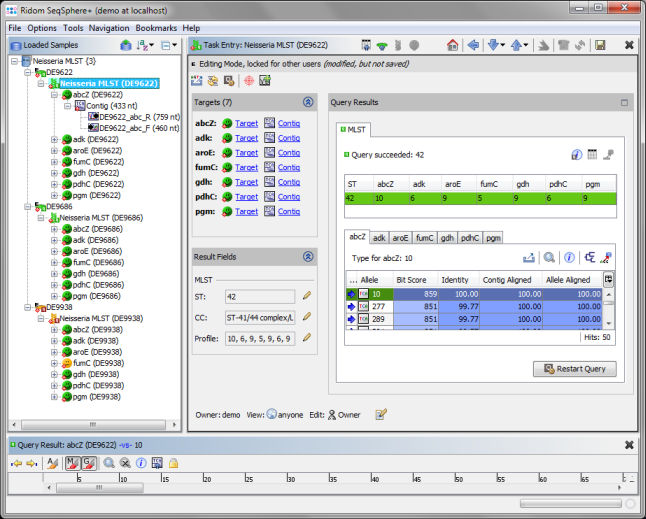
- Step 7: The MLST results are shown in the right panel of the main window. The combination of the 7 MLST loci of this Sample corresponds to ST 42.
- Step 8: 2 of the 3 Samples have green icons (
 ), which means that the analysis succeeds for all 7 MLST loci. But Sample D9938 has a yellow icon (
), which means that the analysis succeeds for all 7 MLST loci. But Sample D9938 has a yellow icon ( ) because target fumC of this Sample has failed in the analysis. Double click on the yellow target icon
) because target fumC of this Sample has failed in the analysis. Double click on the yellow target icon  of target fumC in Sample D9938 to see the details.
of target fumC in Sample D9938 to see the details.
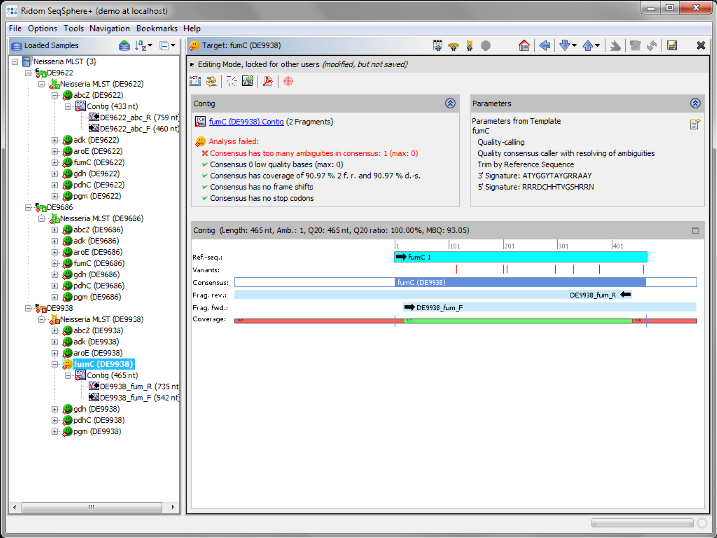
- Step 9: As shown in the warning message on the right, target fumC of this Sample has failed too many ambiguities. Click on the Contig link right of the icon to navigate to the contig level.
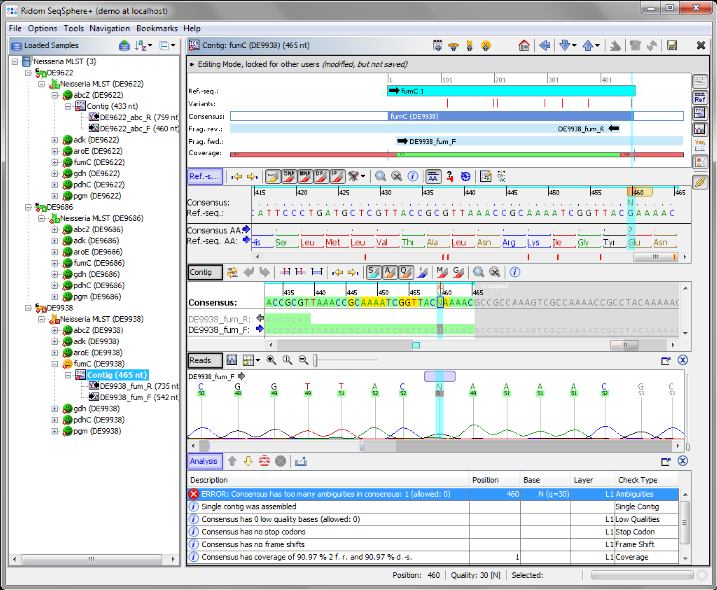
- Step 10: There is an ambiguity symbol N in the read data. This is a wrong base-call in the chromatogram. Click on the position of the N to set the focus there. Obviously the correct base on this position should be a G. Press the
Gon your keyboard to substitute the ambiguity N with a G base.
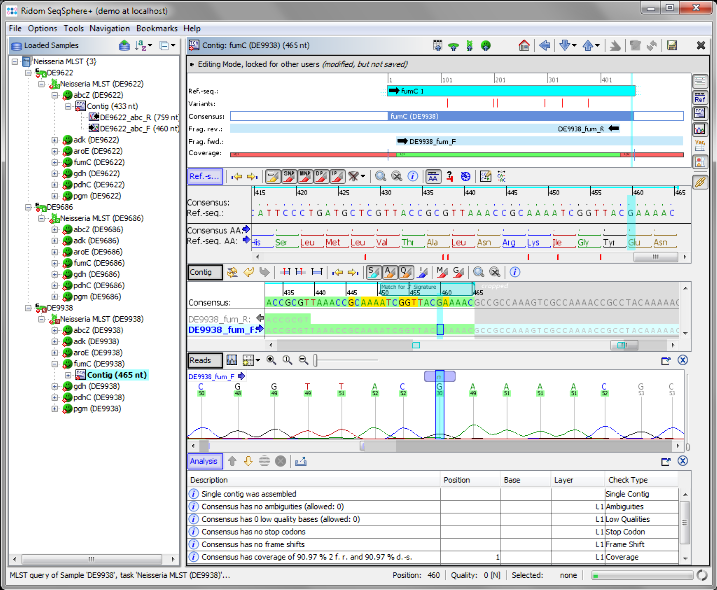
- Step 11: The analysis is automatically updated. The Sample D9938 has now a green icon (), the analysis in all targets has succeeded. All edits are logged in an audit trail. Right-click on the Sample node in the navigation tree, and select
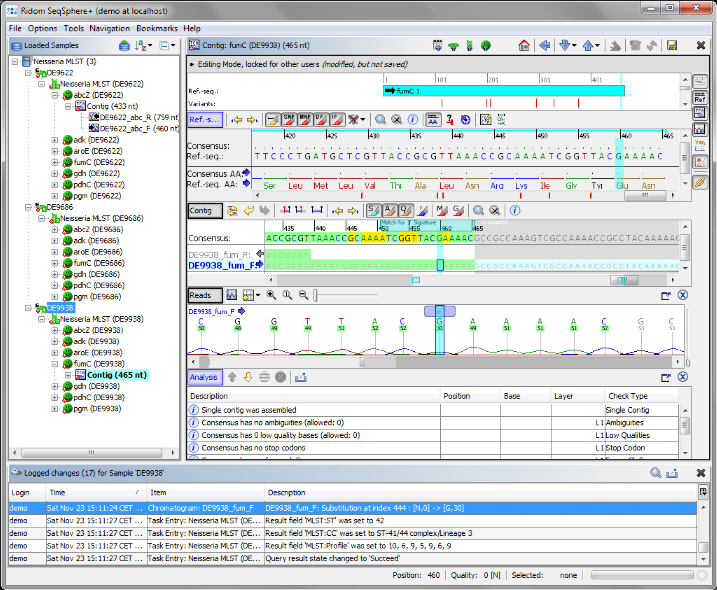
 Show Sample Audit Trail. A new panel appears on the bottom of the main window, listing the history of the Sample entry with detailed information about all edits (who, when, and what).
Show Sample Audit Trail. A new panel appears on the bottom of the main window, listing the history of the Sample entry with detailed information about all edits (who, when, and what).
5 Store and Retrieve Samples
- Step 1: Choose from the menu
 File | Save All to store the 3 Samples to the database on your SeqSphere+ server.
File | Save All to store the 3 Samples to the database on your SeqSphere+ server.
- Step 2: Choose File | Close All to remove them from the workspace
- Step 3: Choose
 File | Search in Database. Select the Neisseria MLST project in the Project box, and choose 1 days for Recently modified. Then press the Search button.
File | Search in Database. Select the Neisseria MLST project in the Project box, and choose 1 days for Recently modified. Then press the Search button.
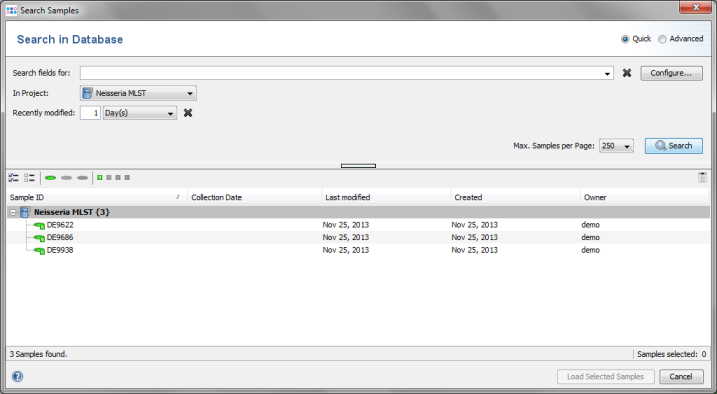
- Step 4: The 3 Samples that just were saved are listed. Now select the Advanced radio button in the upper right corner of the window.
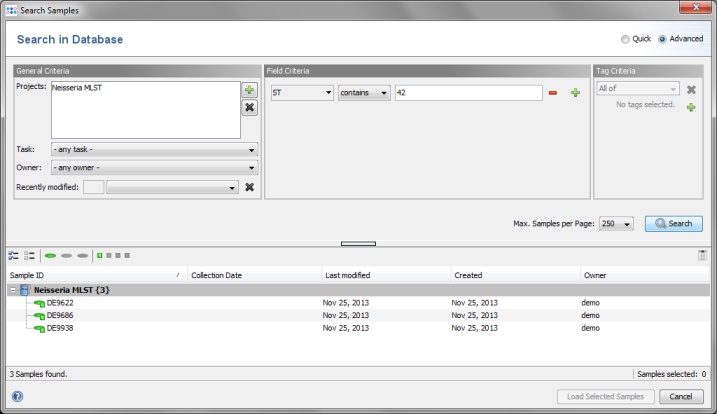
- Step 5: The window now shows the advanced search mask that can be used to search in specific fields (e.g., Neisseria MLST ST = 42).
6 Analyzing the MLST Results
- Step 1: Invoke
 Tools | Comparison Table from the menu bar. Then press the button New Definition.
Tools | Comparison Table from the menu bar. Then press the button New Definition.
- Step 2: Now enter a name for the Comparison Table (e.g., Neisseria MLST), and choose your new Neisseria MLST project to which the Samples were saved.
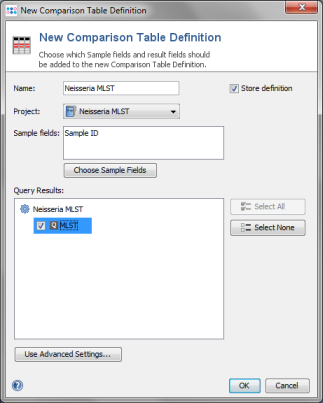
- Step 3: Select the checkbox MLST in the Query Result panel and confirm the dialog window with OK.
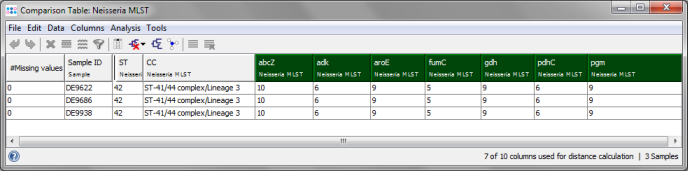
- Step 4: The comparison table window opens, showing the ST, the CC, and the 7 allele types of the 3 Samples. The comparison table can be used to create phylogenetic trees (neighbor-joining or UPGMA), to export the distance matrix for further usage (e.g., for SplitsTree), or to create minimum spanning trees. Press the
 Minimum Spanning Tree button in the toolbar to calculate and draw a minimum spanning tree for the 3 Samples.
Minimum Spanning Tree button in the toolbar to calculate and draw a minimum spanning tree for the 3 Samples.
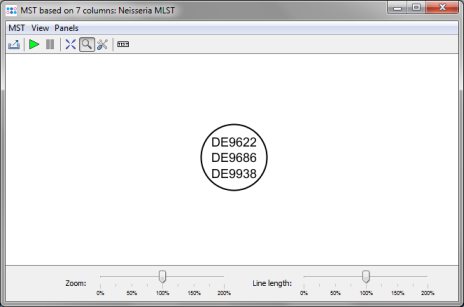
- Step 5: The minimum spanning tree window is opened. However, all 3 Samples collapse to a single node, because all have the same ST 42.