

Contents
Overview
The Sequencing Run Details in SeqSphere+ contain the details of a sequencing run an Illumina platform. They are automatically read and imported by a SeqSphere+ assembling pipeline, if the required Illumina run info files (see below) are found together with the FASTQ files. The Sequencing Run Details are stored in the database and can be used for further quality control on run level.
![]() Important: For importing Sequencing Run Details on a Windows client computer the Windows Subsystem For Linux is required or the Microsoft Visual C++ 2015 libraries must be installed.
Important: For importing Sequencing Run Details on a Windows client computer the Windows Subsystem For Linux is required or the Microsoft Visual C++ 2015 libraries must be installed.
Required Illumina Run Files
The following Illumina run directories and files are required to import Sequencing Run Details:
- Directory InterOp (complete directory)
- File RunInfo.xml
- File RunParameters.xml
- File SampleSheet.csv
If the pipeline is defined to import FASTQ files from a Directory, this directory must contain the InterOp directory and all other required files mentioned above. If the InterOp folder is not available or SeqSphere+ cannot read it, some values would be missed. These figures are Cluster Density, percentage of reads passing Q30, Error Rate and Output number of bases. If the input source type of the pipeline is a MiSeq Repository, the run files are automatically detected and imported from the run folder.
When importing samples in a pipeline, SeqSphere+ compares the imported sample names with names indicated in the SampleSheet.csv. If any of the processed samples do not appear in the sample sheet, a warning message is written in the pipeline log. If a sample that is listed in the sample sheet is missed, no warning message is stated. However, both, extra and missing samples are listed and are highlighted in the Sequencing Run Details window.
Sequencing Run Details Quality Control
The sequencing run details are automatically quality controlled for the two parameters %>=Q30 and Cluster Density. Warnings are given if a parameters does not succeed the following thresholds:
| %>=Q30 | Cluster Density (with added accuracy) | |
|---|---|---|
| MiSeq Reagent Kit v2 | ≥90% for 25 bp ≥80% for 150 bp ≥75% for 250 bp |
≤965 k/mm² |
| MiSeq Reagent Kit v3 | ≥85% for 75 bp ≥70% for 300 bp |
≤1400 k/mm² |
| NextSeq | ≥75% for 150 bp ≥80% for 75 bp |
≤165 k/mm² |
The thresholds are based on the Illumina specifications for MiSeq and NextSeq.
Browse Sequencing Run Details
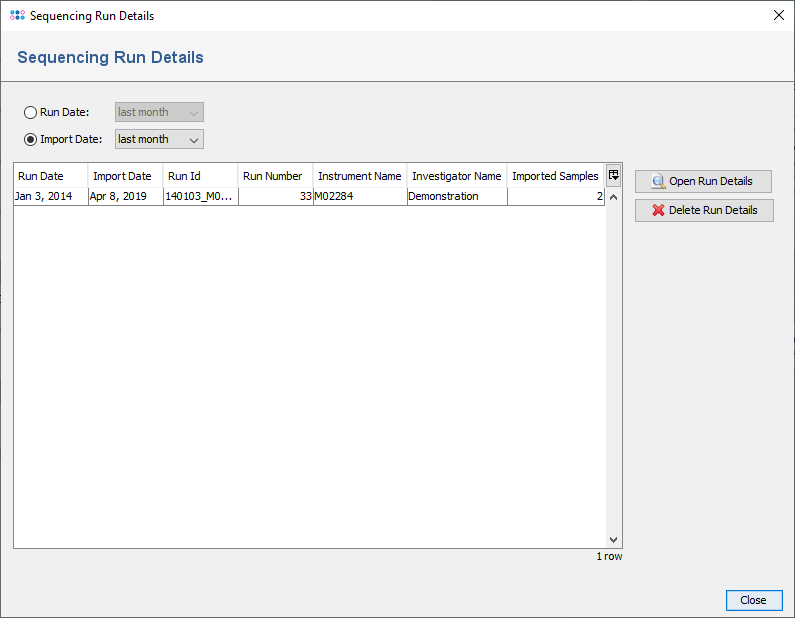
The stored Sequencing Run Details can be accessed in SeqSphere+ using the menu Options | Sequencing Run Details....
The table shows the stored Sequencing Run Details, filtered by one of the two time criteria:
- Run Date: the date when the sequencing run was started, or
- Import Date: the date when the Sequencing Run Details were imported to the SeqSphere+ database.
By double-clicking on a row in the table or by selecting a row and pressing the button Open Run Details, the details of a run can be opened in a new dialog window.
Alternatively, the the run details can also be opened by right-clicking on the field Sequencing Run ID in the procedure tab of a loaded sample.
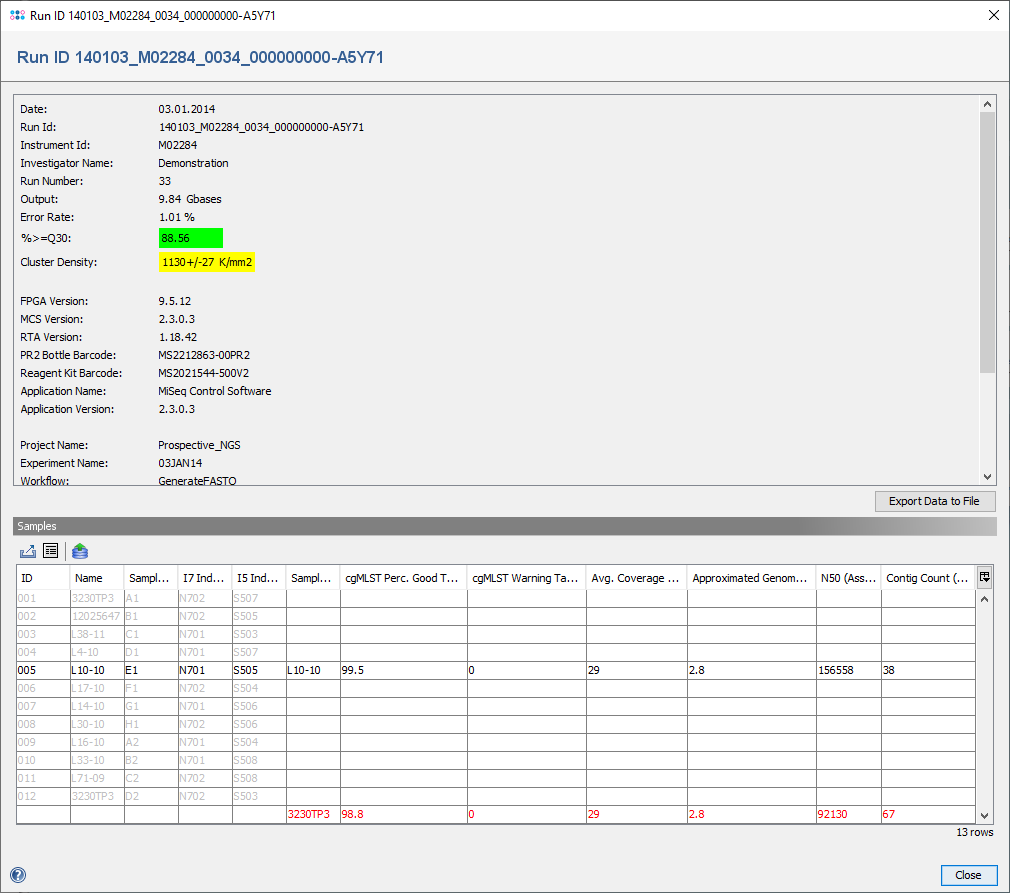
When the window is opened, it contains in the upper part the parameters for the sequencing run. The two quality checked parameters %>=Q30 and Cluster Density are highlighted green if they pass the quality control, else they are highlighted yellow. The tooltips for those fields show the recommended ranges for the values according to kit version and read length.
Below the parameters, the sample sheet is listed in a table together with the samples that were already processed. The first five columns are values from the sample sheet, the sixth (Sample ID) and following columns are values from the processed samples. Grayed out rows (that have only the first fifth columns filled-in) are samples that are defined in the sample sheet, but were not yet processed. Red colored rows (that have only the sixth and following columns filled-in) are samples that were processed, but were not found in the sample sheet.
The processed samples can be directly opened from this table by selecting them and using the ![]() load button.
load button.
The parameters, the samples table, and the original sample sheet can be exported.