

Contents
Submitting Samples
The cgMLST.org Nomenclature Server (www.cgMLST.org) provides a global nomenclature for stable public cgMLST schemes, i.e. for Task Template that were downloaded from the Task Template Sphere. If Samples are using those downloaded Task Templates they can be submitted to cgMLST.org. However, if a Sample has new alleles that are not known at cgMLST.org, then the Sample must be submitted with some minimum data to retrieve newly assigned allele types for them. Otherwise the new alleles are treated as missing data in distance calculation.
![]() Important: If no submission of any data is wanted or allowed, then only local Task Templates must be used. Samples that are using only local Task Templates will not and cannot be submitted to cgMLST.org. Local Task Templates can be defined using the cgMLST Target Definer, or by converting public Task Templates into local ones.
Important: If no submission of any data is wanted or allowed, then only local Task Templates must be used. Samples that are using only local Task Templates will not and cannot be submitted to cgMLST.org. Local Task Templates can be defined using the cgMLST Target Definer, or by converting public Task Templates into local ones.
The submission of a Sample requires the following minimum data:
- Sample ID (alternatively Alias ID or do not submit and use Ridom ID)
- Submitter Info (not shown public)
- Submission Date (only year is shown public)
- MLST Sequence Type (ST)
- Core and accessory genome MLST allelic profiles
- cgMLST Cluster Type (CT, returned from cgMLST.org)
- Percentage of Good cgMLST Targets
- Genus
- Species
The amount of additional metadata that should be submitted can be defined in the Submission Anonymization Filter.
Submission to cgMLST.org is only possible if the Sample has in the cgMLST scheme at least 90% of good targets (i.e., targets passed the QC procedure and have therefore a green or yellow smiley). Allele types are only received for the good targets (green or yellow smiley). During the first submission, the user must register once with basic contact information. This information can later be modified using the menu function Options | User Settings. The submitter contact information is not public shown on cgMLST.org, but it will be used to forward incoming requests about submitted Samples.
Except for the submitter information and exact submission date any submitted data is immediately made publicly available on cgMLST.org. A unique serial number is assigned to the sample, and stored back as Ridom ID in the local database. This number is also shown as link in the upper right corner of the Sample Overview. This Ridom ID link can be used to directly access the public web page of the submitted Sample and to control the data that was submitted (e.g. RID002433).
There are two different ways in SeqSphere+ to submit Samples to cgMLST.org:
Manual Submission
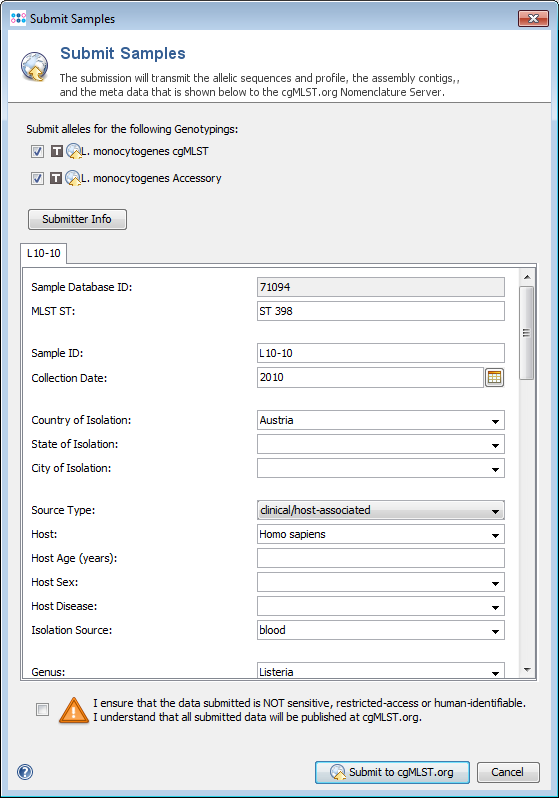
- Step 1: Load the Sample(s) into the workspace using the menu function File | Search Samples.
- Step 2: Invoke the menu function File | Assign or Submit new Alleles and select all Samples that should be submitted.
- Step 3: The Submission Anonymization Filter dialog is shown to define which fields should be submitted. The last used setting is kept.
- Step 4: Finally the Submission Preview dialog is shown with the filtered data that will be submitted. The data can now be controlled and modified just before sending it. When the dialog is confirmed, the shown data is send to cgMLST.org.
Submission via Pipeline
If Samples are imported through a pipeline, it can be configured in the Submission part of the Pipeline Script that the Samples are submitted to cgMLST.org. The Submission Anonymization Filter settings are defined for each pipeline script.
In contrast to the manual submission, the pipeline submission does not show a preview dialog before the samples are submitted, because all pipeline processing runs in an automatized way. Therefore, the button Preview Epi Data can be used to show the potentially submitted epi data of the matching samples that already exist in the SeqSphere+ server database.
Resubmitting Samples
If a Sample that was already submitted is submitted again, then the data at cgMLST.org is immediately updated. Fields that are filtered out or set to empty in the re-submission are immediately removed from cgMLST.org.
The procedure for re-submitting Samples is the same as described above in the manual submission section.
Filtering Metadata for Submission
The level of metadata that should be submitted can be defined in the Submission Anonymization Filter that is shown in a dialog before a manual submission is confirmed. Also in a pipeline script the Submission Anonymization Filter settings can be configured if automatic submission is selected.
New epidemiological fields that are created by the user are never submitted.
Potentially the following metadata is submitted to cgMLST.org and shown on the public website. Unless the fields are mandatory, they can be excluded from submission (Do Not Submit). For place and time information additionally the level of detail can be set. The table shows the default settings for a new installation of a SeqSphere+ Client.
| Submission Info | |
|---|---|
| Submitter Info | Submit (mandatory, not public) |
| Submission Date | Submit (mandatory, only year is public) |
| Sample Ridom ID | Submit (generated by cgMLST.org) |
| Genotyping Result | |
| MLST ST | Submit (mandatory) |
| cgMLST/Acc. Allelic Profile | Submit (mandatory) |
| cgMLST Cluster Type | Submit (mandatory) |
| Perc. Good cgMLST Targets | Submit (mandatory) |
| Sequence Data | |
| Assembly Contigs (FASTA) | Submit |
| Epi Basic | |
| Sample ID | Submit |
| Alias ID | Do Not Submit (alternative for Sample ID) |
| Collection Date | Submit |
| Epi Source | |
| Country of Isolation | Submit |
| State of Isolation | Submit |
| City of Isolation | Submit |
| Source Type | Submit |
| Host | Submit |
| Host Age (years) | Submit |
| Host Sex | Submit |
| Host Disease | Submit |
| Isolation Source | Submit |
| Epi Characteristic | |
| Genus | Submit (mandatory) |
| Species | Submit (mandatory) |
| Strain | Submit |
| Genotype | Submit |
| Serotype | Submit |
| Pathotype | Submit |
| Identification Method | Submit |
| Identification Kit Vendor | Submit |
| Culture Collection | Submit |
| PubMed ID(s) | Submit |
| Nuccleotide Accession(s) | Submit |
| Experiment Accession | Submit |
| Sample Accession | Submit |
| StudyAccession | Submit |
| Imported from EBI/NCBI1) | Submit (mandatory) |
| Epi Species Specific | |
| PFGE Pattern(s) | Submit |
| Epi Species Specific (only for MTBC) | |
| Spoligo | Submit |
| MIRU 15-9 Type | Submit |
| MIRU Lineage | Submit |
| Gagneux Lineage | Submit |
| Laboratory Procedure Details | |
| Nucleic Acid Extraction | Submit |
| Library Source | Submit |
| Library Strategy | Submit |
| Library Selection | Submit |
| Library Construction Method | Submit |
| Library Amplification Method | Submit |
| Sequencing Protocol | Submit |
| Library Insert Size | Submit |
| Sequencing Length | Submit |
| Sequencing Vendor | Submit |
| Sequencing Platform | Submit |
| Assembly Procedure Details | |
| Assembly Pre-processing | Submit |
| Assembly Type | Submit |
| Mapping Reference Genome | Submit |
| Assembler | Submit |
| Assembler Version | Submit |
| Assembler Parameters | Submit |
| Read Statistics | |
| Avg. Coverage (Unassembled) | Submit |
| Avg. Read Length (Unassembled) | Submit |
| Avg. Read Length (Processed, Unassembled) | Submit |
| Assembly Statistics | |
| Contig Count (Assembled) | Submit |
| N50 (Assembled) | Submit |
| Consensus Base Count (Assembled) | Submit |
| Avg. Coverage (Assembled) | Submit |
| Genome Status1) | Submit (mandatory) |
1) The fields Imported from EBI/NCBI and Genome Status are automatically filled if the data was imported from NCBI Genomes or SRA. Imported from EBI/NCBI can be true or false. The Genome Status can have one of the following values: Complete Genome, Chromosome, Scaffold, Contig, or SRA.